Scalable Web Architecture and Distributed Systems
可扩展Web架构与分布式系统
Open source software has become a fundamental building block for some of the biggest websites. And as those websites have grown, best practices and guiding principles around their architectures have emerged. This chapter seeks to cover some of the key issues to consider when designing large websites, as well as some of the building blocks used to achieve these goals.
开源软件已 经成为构建最大的一些网站的基石.随着这些网站规模的增长,围绕它们的架构出现了许多最佳实践与指导原则.
这篇文章旨在涉及一些在设计大型网站时需要考虑的关键问题和一些为达到这些目标所使用的组件
This chapter is largely focused on web systems, although some of the material is applicable to other distributed systems as well.
本章主要讲Web系统,不过一些内容也适用于其他分布式系统
1.1. Principles of Web Distributed Systems Design Web分布式系统设计原则
What exactly does it mean to build and operate a scalable web site or application? At a primitive level it’s just connecting users with remote resources via the Internet—the part that makes it scalable is that the resources, or access to those resources, are distributed across multiple servers.
构建和运作可扩展网站或者Web应用,到底意味着什么?说到底这些系统只是通过互联网将用户与远程资源连接而已,它们之所以变成可扩展的,是因为资源或者对资源的访问是跨多个服务器分布的
Like most things in life, taking the time to plan ahead when building a web service can help in the long run; understanding some of the considerations and tradeoffs behind big websites can result in smarter decisions at the creation of smaller web sites. Below are some of the key principles that influence the design of large-scale web systems:
与现实生活中的大多数事情一样,构建Web服务的过程中花些时间预先计划从长远来看是有帮助的。理解了大型网站背后的考虑因素和取舍,开发较小的网站时你就能够做出更明智的决策。影响大规模Web系统设计的一些关键原则如下
Availability: The uptime of a website is absolutely critical to the reputation and functionality of many companies. For some of the larger online retail sites, being unavailable for even minutes can result in thousands or millions of dollars in lost revenue, so designing their systems to be constantly available and resilient to failure is both a fundamental business and a technology requirement. High availability in distributed systems requires the careful consideration of redundancy for key components, rapid recovery in the event of partial system failures, and graceful degradation when problems occur.
可用性 网站的正常运行时间对许多公司的声誉和功能至关重要。对于一些规模较大的在线零售网站,即使几分钟都不可用,也可能导致数千或数百万美元的收入损失,因此,将其系统设计为持续可用并能够抵御失败既是一项基本业务,也是一项技术要求。分布式系统中的高可用性需要仔细考虑关键组件的冗余、在部分系统故障时快速恢复以及出现问题时的优雅降级。
Performance: Website performance has become an important consideration for most sites. The speed of a website affects usage and user satisfaction, as well as search engine rankings, a factor that directly correlates to revenue and retention. As a result, creating a system that is optimized for fast responses and low latency is key.
性能 网站性能已成为大多数网站的重要考虑因素。网站的速度会影响使用率和用户满意度,以及搜索引擎排名,这是一个与收入和留存率直接相关的因素。因此,创建一个针对快速响应和低延迟进行优化的系统是关键。
Reliability: A system needs to be reliable, such that a request for data will consistently return the same data. In the event the data changes or is updated, then that same request should return the new data. Users need to know that if something is written to the system, or stored, it will persist and can be relied on to be in place for future retrieval.
可靠性 一个系统需要可靠,这样对数据的请求将一致地返回相同的数据。如果数据发生更改或更新,则同一请求应返回新数据。用户需要知道,如果某个东西被写入或存储到系统中,它将持续存在,并且将来可以依赖于它的存在。
Scalability: When it comes to any large distributed system, size is just one aspect of scale that needs to be considered. Just as important is the effort required to increase capacity to handle greater amounts of load, commonly referred to as the scalability of the system. Scalability can refer to many different parameters of the system: how much additional traffic can it handle, how easy is it to add more storage capacity, or even how many more transactions can be processed.
可扩展性 提到任何大型分布式系统时,规模只是需要考虑的一个方面。同样重要的是,为了处理更大的负载(通常称为系统的可扩展性),需要增加容量。可扩展性可能是指系统的各个的参数:它可以处理多少额外的流量,增加更多的存储容量有多容易,甚至可以处理多少事务
Manageability: Designing a system that is easy to operate is another important consideration. The manageability of the system equates to the scalability of operations: maintenance and updates. Things to consider for manageability are the ease of diagnosing and understanding problems when they occur, ease of making updates or modifications, and how simple the system is to operate. (I.e., does it routinely operate without failure or exceptions?)
易管理性 设计一个易于操作的系统是另一个重要考虑因素。系统的可管理性等同于操作的可伸缩性:维护和更新。对于可管理性,需要考虑的是在问题发生时诊断和理解问题的容易程度,更新或修改的容易程度,以及系统操作的简单程度。(即,它是否正常运行而无故障或异常?)
Cost: Cost is an important factor. This obviously can include hardware and software costs, but it is also important to consider other facets needed to deploy and maintain the system. The amount of developer time the system takes to build, the amount of operational effort required to run the system, and even the amount of training required should all be considered. Cost is the total cost of ownership.
成本 成本是一个重要的因素.很明显它包括硬件和软件成本,但是考虑部署和维护系统所需的其他方面也很重要。系统构建所需的开发人员时间、运行系统所需的操作工作量,甚至所需的培训量都应该考虑在内。成本是总拥有成本。
Each of these principles provides the basis for decisions in designing a distributed web architecture. However, they also can be at odds with one another, such that achieving one objective comes at the cost of another. A basic example: choosing to address capacity by simply adding more servers (scalability) can come at the price of manageability (you have to operate an additional server) and cost (the price of the servers).
这些原则中的每一条都为设计分布式Web体系结构的决策提供了基础。然而,它们之间也可能存在分歧,导致实现一个目标是以另一个目标为代价的。一个基本的例子:选择通过简单地添加更多的服务器来解决容量问题(可伸缩性)可能要以可管理性(必须操作一个额外的服务器)和成本(服务器的价格)为代价。
1.2. The Basics 基本原理
When it comes to system architecture there are a few things to consider: what are the right pieces, how these pieces fit together, and what are the right tradeoffs. Investing in scaling before it is needed is generally not a smart business proposition; however, some forethought into the design can save substantial time and resources in the future.
当提到系统体系结构时,有几个问题需要考虑:什么是正确的组件,这些组件如何协作,需要做哪些正确的权衡。在真正需要可扩展性之前就花时间和精力投入其中从商业上来看不是一个明智的建议;但是,一些设计中的远见卓识将会在未来节省大量的时间和资源。
This section is focused on some of the core factors that are central to almost all large web applications: services, redundancy, partitions, and handling failure. Each of these factors involves choices and compromises, particularly in the context of the principles described in the previous section. In order to explain these in detail it is best to start with an example.
本节着眼于一些对于几乎所有大型Web应用都非常核心的要素:服务,冗余,分区和失败处理。每个要素均牵涉到选择和妥协,特别是在上一节提到的准则上下文中。为了更好的说明我们从一个例子开始。
Example: Image Hosting Application 举例:图片托管应用
At some point you have probably posted an image online. For big sites that host and deliver lots of images, there are challenges in building an architecture that is cost-effective, highly available, and has low latency (fast retrieval).
你很可能已经在网上上传过一张图片。对于托管和传输大量图片的大型网站来说,构建一个低成本、高可用性和低延迟(能够快速检索)的体系结构存在挑战。
Imagine a system where users are able to upload their images to a central server, and the images can be requested via a web link or API, just like Flickr or Picasa. For the sake of simplicity, let’s assume that this application has two key parts: the ability to upload (write) an image to the server, and the ability to query for an image. While we certainly want the upload to be efficient, we care most about having very fast delivery when someone requests an image (for example, images could be requested for a web page or other application). This is very similar functionality to what a web server or Content Delivery Network (CDN) edge server (a server CDN uses to store content in many locations so content is geographically/physically closer to users, resulting in faster performance) might provide.
设想一个这样的系统:用户可以将他们的图片上传到一个中央服务器,并且图片可以通过web链接或者API(应用程序接口)进行请求,就像Flickr或者Picasa一样。为了简单起见,我们假定这个应用有两个关键部分:能够上传(写入)一张图片到服务器,能够查询一张图片。虽然我们希望上传能够更快速,但我们最关心的是系统能够快速分发用户请求的图片(比如图片可以被请求用于一张网页或是其他应用)。这些跟一个web服务器或者CDN(内容分发网络) edge server(CDN所使用的服务器,用于在很多位置存放内容,这样内容在地理/物理上更接近用户,起到更高性能的作用)所提供的功能非常类似。
Other important aspects of the system are:
- There is no limit to the number of images that will be stored, so storage scalability, in terms of image count needs to be considered.
- There needs to be low latency for image downloads/requests.
- If a user uploads an image, the image should always be there (data reliability for images).
- The system should be easy to maintain (manageability).
- Since image hosting doesn’t have high profit margins, the system needs to be cost-effective
Figure 1.1 is a simplified diagram of the functionality.
系统的其他重要方面包括:
对于存储的图片数量没有设限,所以就图片数量而言,需要考虑存储的可扩展性。
图片下载/请求需要做到低延迟。
如果一个用户上传了一张图片,那该图片应该总是存在的(图像的数据可靠性)。
系统应该易于维护(可管理性)。
由于图片托管没有很高的利润率,系统需要低成本。
图1.1是功能的简化图。
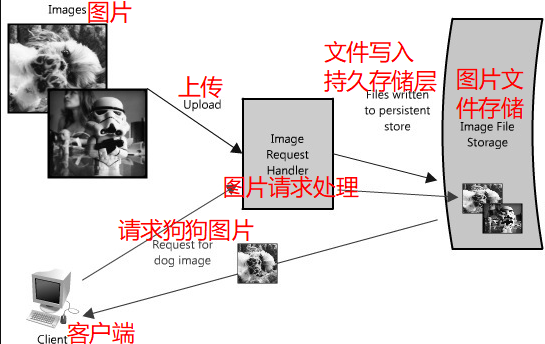
Figure 1.1: Simplified architecture diagram for image hosting application
图1.1:图像托管应用程序的简化架构图
In this image hosting example, the system must be perceivably fast, its data stored reliably and all of these attributes highly scalable. Building a small version of this application would be trivial and easily hosted on a single server; however, that would not be interesting for this chapter. Let’s assume that we want to build something that could grow as big as Flickr.
在这个图片托管示例中,系统必须做到(让用户)可感知到快速,存储数据的可靠性和那些所有高可扩展性的特征。构建一个小型的托管于单台服务器上的应用过于简单,也没有意义,对于本章来说也没有乐趣所在。来假设下,我们想要构建出可以成长为像Flickr一样的庞然大物。
Services 服务
When considering scalable system design, it helps to decouple functionality and think about each part of the system as its own service with a clearly defined interface. In practice, systems designed in this way are said to have a Service-Oriented Architecture (SOA). For these types of systems, each service has its own distinct functional context, and interaction with anything outside of that context takes place through an abstract interface, typically the public-facing API of another service.
在考虑可伸缩系统设计时,使用明确定义的接口有助于将功能解耦,并将系统的每个部分视为一个服务。在实践中,以这种方式设计的系统被称为面向服务的体系结构(SOA)。对于这些类型的系统,每个服务都有它们各自确切的功能上下文,并且和该上下文以外的任何交互均是与一个抽象的接口(通常是另一个服务暴露的API)进行的。
Deconstructing a system into a set of complementary services decouples the operation of those pieces from one another. This abstraction helps establish clear relationships between the service, its underlying environment, and the consumers of that service. Creating these clear delineations can help isolate problems, but also allows each piece to scale independently of one another. This sort of service-oriented design for systems is very similar to object-oriented design for programming.
将一个系统分解成一组互补的服务,可以使服务彼此解耦。这种抽象有助于在服务、服务的底层(运行)环境和该服务的消费者之间建立清晰的关系。创建这些清晰的描述有助于隔离问题,并且也允许每个部分独立地进行扩展。这种面向服务的系统设计与面向对象的程序设计非常相似。
In our example, all requests to upload and retrieve images are processed by the same server; however, as the system needs to scale it makes sense to break out these two functions into their own services.
在我们的示例中,上传和检索图像的所有请求都是由同一服务器处理的;但是,由于系统需要进行扩展,有必要将这两个功能分解为独立的服务。
Fast-forward and assume that the service is in heavy use; such a scenario makes it easy to see how longer writes will impact the time it takes to read the images (since they two functions will be competing for shared resources). Depending on the architecture this effect can be substantial. Even if the upload and download speeds are the same (which is not true of most IP networks, since most are designed for at least a 3:1 download-speed:upload-speed ratio), read files will typically be read from cache, and writes will have to go to disk eventually (and perhaps be written several times in eventually consistent situations). Even if everything is in memory or read from disks (like SSDs), database writes will almost always be slower than reads. (Pole Position, an open source tool for DB benchmarking, http://polepos.org/ and results http://polepos.sourceforge.net/results/PolePositionClientServer.pdf.).
快进下,假设服务正在大量使用;这样的场景很容易观测到写入时间多长时将影响读取图片所需的时间(因为这两个功能将争夺共享资源)。在这样的架构下,这种影响是真实存在的。即使上传和下载速度相同(大多数IP网络并非如此,因为大多数都是设计成下载速度与上传速度3:1的比例),文件通常直接从缓存中读取,而写入则最终必须到达磁盘(在最终一致的场景中可能会被写入多次)。即使所有东西都是从内存或者磁盘(比如SSD固态硬盘)读取,数据库的写入操作几乎总是比读取要慢。(Pole Position,一个用于数据库基准测试的开源工具,http://polepos.org/和结果http://polepos.sourceforge.net/results/polepositionclientserver.pdf.)。
Another potential problem with this design is that a web server like Apache or lighttpd typically has an upper limit on the number of simultaneous connections it can maintain (defaults are around 500, but can go much higher) and in high traffic, writes can quickly consume all of those. Since reads can be asynchronous, or take advantage of other performance optimizations like gzip compression or chunked transfer encoding, the web server can switch serve reads faster and switch between clients quickly serving many more requests per second than the max number of connections (with Apache and max connections set to 500, it is not uncommon to serve several thousand read requests per second). Writes, on the other hand, tend to maintain an open connection for the duration for the upload, so uploading a 1MB file could take more than 1 second on most home networks, so that web server could only handle 500 such simultaneous writes.
这种设计的另一个潜在问题是,像Apache 或lighttpd这样的Web服务器,通常有一个它可以维持并发连接数的上线(默认大约在500左右,但可以调得更高),并且在高流量下,写操作将很快消耗完所有(连接资源)。不过由于读操作可以异步进行,或者利用其它性能优化手段如gzip压缩或者分块传输编码,Web服务器可以更快地切换服务读操作、更快切换客户端,从而比最大连接数每秒服务更多的请求(Apache和最大连接数设置为500,但一般都能每秒服务数千个请求)。另一方面,上传时写入操作往往会保持一个打开状态的连接,所以上传一个1M大小的文件在大多数家庭网络上将花费超过1秒的时间,因此Web服务器只能同时处理500个写入操作。

Figure 1.2: Splitting out reads and writes
图1.2:读写分离
Planning for this sort of bottleneck makes a good case to split out reads and writes of images into their own services, shown in Figure 1.2. This allows us to scale each of them independently (since it is likely we will always do more reading than writing), but also helps clarify what is going on at each point. Finally, this separates future concerns, which would make it easier to troubleshoot and scale a problem like slow reads.
将图片的读、写操作拆分成各自的服务是一个应对这种瓶颈很好的解决方案,如图1.2所示。我们能够独立的扩展它们(一般读总是多余写),同时也有助于理清每一个服务中发生的事情。最后,这样做分离了未来的隐患,可以更简单地解决像读操作缓慢的问题,并做到可伸缩。。
The advantage of this approach is that we are able to solve problems independently of one another—we don’t have to worry about writing and retrieving new images in the same context. Both of these services still leverage the global corpus of images, but they are free to optimize their own performance with service-appropriate methods (for example, queuing up requests, or caching popular images—more on this below). And from a maintenance and cost perspective each service can scale independently as needed, which is great because if they were combined and intermingled, one could inadvertently impact the performance of the other as in the scenario discussed above.
这种方法的优点在于我们能够独立(不影响其他)解决问题——我们不用担心在同一上下文中写入、读取新的图片。这两者(服务)仍然影响着全部的图片,但均能通过service-appropriate方法优化它们的性能(比如让请求排队,或者缓存热点图片——更多种方式请见下文)。从一个维护和成本的角度来看,每个服务均能独立、按需扩展是非常好的,因为如上面讨论的场景中所讨论的那样,如果它们被组合、混合在一起,可能某一(服务)不经意间就会影响到其他(服务)的性能。
Of course, the above example can work well when you have two different endpoints (in fact this is very similar to several cloud storage providers’ implementations and Content Delivery Networks). There are lots of ways to address these types of bottlenecks though, and each has different tradeoffs.
当然,当你考虑着两个不同点时,上面的例子能够工作得很好(事实上,这跟一些云存储提供商的实现方案和CDN很类似)。尽管还有很多方法来处理这些类型的瓶颈,但每个都有不同方面的权衡。
For example, Flickr solves this read/write issue by distributing users across different shards such that each shard can only handle a set number of users, and as users increase more shards are added to the cluster (see the presentation on Flickr’s scaling,http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html). In the first example it is easier to scale hardware based on actual usage (the number of reads and writes across the whole system), whereas Flickr scales with their user base (but forces the assumption of equal usage across users so there can be extra capacity). In the former an outage or issue with one of the services brings down functionality across the whole system (no-one can write files, for example), whereas an outage with one of Flickr’s shards will only affect those users. In the first example it is easier to perform operations across the whole dataset—for example, updating the write service to include new metadata or searching across all image metadata—whereas with the Flickr architecture each shard would need to be updated or searched (or a search service would need to be created to collate that metadata—which is in fact what they do).
例如,Flickr通过将用户分布在不同的分片中的方法来解决这个读/写问题,这样每个分片只能处理一组用户,并且随着用户数量的增加,更多的分片会添加到集群中(请参见关于Flickr系统扩展的演示文稿,http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html)。在第一个例子中,根据实际使用情况(整个系统的读写次数)扩展硬件更加容易,而Flickr则根据用户基数来扩展(但强制假定用户之间使用相同,所以可能会有额外的容量)。在前一种情况下,某个服务中断或发生问题会降低整个系统的功能性(例如,没有人可以写入文件),然而Flickr的一个分片的中断只会影响该分片的用户。。第一个例子易于操作整个数据集,比如升级写入服务来包含新的元数据或者搜索所有的图片元数据,然而在Flickr的架构下,每个分片均需要被更新或搜索(或者需要创建搜索服务以对元数据进行排——事实上他们确实这么做)
When it comes to these systems there is no right answer, but it helps to go back to the principles at the start of this chapter, determine the system needs (heavy reads or writes or both, level of concurrency, queries across the data set, ranges, sorts, etc.), benchmark different alternatives, understand how the system will fail, and have a solid plan for when failure happens.
对于这些系统来说没有孰对孰错,而是帮助我们回到本章开头所说的准则,判断系统需求(读多还是写多还是两者都多,并发程度,跨数据集查询,搜索,排序等),检测不同的取舍,理解系统为什么会失败并且有可靠的计划来应对失败的发生。
Redundancy 冗余
In order to handle failure gracefully a web architecture must have redundancy of its services and data. For example, if there is only one copy of a file stored on a single server, then losing that server means losing that file. Losing data is seldom a good thing, and a common way of handling it is to create multiple, or redundant, copies.
为了优雅地处理故障,Web体系结构必须具有服务和数据的冗余。例如,如果一台服务器上只存储了一份文件,那么丢失该服务器就意味着丢失该文件。丢失数据很糟糕,处理它的常见方法是创建多个或冗余的副本。
This same principle also applies to services. If there is a core piece of functionality for an application, ensuring that multiple copies or versions are running simultaneously can secure against the failure of a single node.
同样的原则也适用于服务。如果应用程序有一个核心功能,确保同时运行多个副本或版本可以防止单个节点的故障。
Creating redundancy in a system can remove single points of failure and provide a backup or spare functionality if needed in a crisis. For example, if there are two instances of the same service running in production, and one fails or degrades, the system can failoverto the healthy copy. Failover can happen automatically or require manual intervention.
在系统中创建冗余可以消除单点故障,并提供一个备份或在必要的紧急时刻替换功能。例如,如果在生产环境有同一服务的两个实例在运行,其中一个发生故障或降级了,系统可以(启动)failover到那个健康状态的服务。Failover可以自动发生或者需要人工干预。
Another key part of service redundancy is creating a shared-nothing architecture. With this architecture, each node is able to operate independently of one another and there is no central “brain” managing state or coordinating activities for the other nodes. This helps a lot with scalability since new nodes can be added without special conditions or knowledge. However, and most importantly, there is no single point of failure in these systems, so they are much more resilient to failure.
服务冗余的另一个关键点在于创建一个非共享的架构(即无状态架构)。通过这种架构,每个节点都能够独立操作,并且没有中央“大脑”来管理状态或者协调其他节点的活动。这对于可扩展性非常有帮助,因为新的节点不需要特殊的条件或知识就能加入(到集群)。但是,最重要的是在这些系统中不会存在单点失败问题,所以它们能够更加弹性地面对失败。
For example, in our image server application, all images would have redundant copies on another piece of hardware somewhere (ideally in a different geographic location in the event of a catastrophe like an earthquake or fire in the data center), and the services to access the images would be redundant, all potentially servicing requests. (See Figure 1.3.) (Load balancers are a great way to make this possible, but there is more on that below).
例如,在我们的图片服务应用中,所有的图片会在另一个地方的硬件中有冗余的备份(理想情况是在一个不同的地理位置,以防地震或者数据中心火灾这类的灾难发生),而访问图片的服务同样是冗余的,,所有可能的服务请求都是冗余的。(见图 1.3)(负载均衡器可以将其变为现实,详情请见下文。)

Figure 1.3: Image hosting application with redundancy
图1.3 具有冗余的图像托管应用程序
Partitions 分区
There may be very large data sets that are unable to fit on a single server. It may also be the case that an operation requires too many computing resources, diminishing performance and making it necessary to add capacity. In either case you have two choices: scale vertically or horizontally.
单台服务器可能没法放下海量数据集。也可能是一个操作需要太多计算资源,消耗性能,使得有必要增加(系统)容量。无论是哪种情况,你都有两种选择:垂直扩展(scale vertically)或者水平扩展(scale horizontally)。
Scaling vertically means adding more resources to an individual server. So for a very large data set, this might mean adding more (or bigger) hard drives so a single server can contain the entire data set. In the case of the compute operation, this could mean moving the computation to a bigger server with a faster CPU or more memory. In each case, vertical scaling is accomplished by making the individual resource capable of handling more on its own.
垂直扩展意味着在单台服务器上增加更多的资源。所以对于大数据来说,这意味着增加更多(更大容量)的硬盘以便让单台服务器能够容纳整个数据集。对于计算操作的场景,这意味着将计算任务交给一台拥有更快CPU或者更多内存的大型服务器。对于每种场景,垂直扩展是通过自身(个体)能够处理更多的方式来达到目标的。
To scale horizontally, on the other hand, is to add more nodes. In the case of the large data set, this might be a second server to store parts of the data set, and for the computing resource it would mean splitting the operation or load across some additional nodes. To take full advantage of horizontal scaling, it should be included as an intrinsic design principle of the system architecture, otherwise it can be quite cumbersome to modify and separate out the context to make this possible.
另一方面,水平扩展就是添加更多的节点。对于大数据集,可能是用另一台服务器来存储部分数据集;而对于计算资源来说,则意味着将操作进行分解或者加载在一些额外的节点上。为了充分利用水平扩展的优势,这(此处指代的是系统支持水平扩展。垂直扩展对于应用来说无需修改,通常升级机器即可达到目的。而水平扩展就要求应用架构能够支持这种方式的扩展,因为数据、服务都是分布式的,需要从软件层面来支持这一特性,从而做到数据、服务的水平可扩展。)应该被天然地包含在系统架构设计准则里,否则想要通过修改、隔离上下文来达到这一点将会相当麻烦。
When it comes to horizontal scaling, one of the more common techniques is to break up your services into partitions, or shards. The partitions can be distributed such that each logical set of functionality is separate; this could be done by geographic boundaries, or by another criteria like non-paying versus paying users. The advantage of these schemes is that they provide a service or data store with added capacity.
对于水平扩展来说,通常方法之一就是将你的服务打散、分区。分区可以是分布式的,这样每个逻辑功能集都是分离的;分区可通过地理边界来划分,或者其他标准如付费/未付费用户。这些设计的好处在于它们能够使得服务或数据存储易于增加容量。
In our image server example, it is possible that the single file server used to store images could be replaced by multiple file servers, each containing its own unique set of images. (See Figure 1.4.) Such an architecture would allow the system to fill each file server with images, adding additional servers as the disks become full. The design would require a naming scheme that tied an image’s filename to the server containing it. An image’s name could be formed from a consistent hashing scheme mapped across the servers. Or alternatively, each image could be assigned an incremental ID, so that when a client makes a request for an image, the image retrieval service only needs to maintain the range of IDs that are mapped to each of the servers (like an index).
在我们的图片服务器例子中,可以将单台存储图片的服务器替换为多台文件服务器,每台保存各自单独的图片集。(见图1.4)这样的架构使得系统能够往各台文件服务器中存入图片,当磁盘快满时再增加额外的服务器。这种设计将需要一种命名机制,将图片的文件名与所在服务器关联起来。一个图片的名字可以通过服务器间一致性Hash机制来生成。或者另一种选择是,可以分配给每张图片一个增量ID,当一个客户端请求一张图片时,图片检索服务只需要维护每台服务器对应的ID区间即可(类似索引)。

Figure 1.4: Image hosting application with redundancy and partitioning
图1.4:具有冗余和分区特性的图片托管应用程序
Of course there are challenges distributing data or functionality across multiple servers. One of the key issues is data locality; in distributed systems the closer the data to the operation or point of computation, the better the performance of the system. Therefore it is potentially problematic to have data spread across multiple servers, as any time it is needed it may not be local, forcing the servers to perform a costly fetch of the required information across the network.
当然,将数据或功能分布在多台服务器上会带来很多挑战。关键问题之一是数据局部性(data locality);在分布式系统里,数据离操作或者计算点越近,系统性能就越高。因此将数据分布在多台服务器可能是有问题的,任何需要(数据)的时候都可能不在本地,使得服务器必须通过网络来获取所需的信息。
Another potential issue comes in the form of inconsistency. When there are different services reading and writing from a shared resource, potentially another service or data store, there is the chance for race conditions—where some data is supposed to be updated, but the read happens prior to the update—and in those cases the data is inconsistent. For example, in the image hosting scenario, a race condition could occur if one client sent a request to update the dog image with a new title, changing it from “Dog” to “Gizmo”, but at the same time another client was reading the image. In that circumstance it is unclear which title, “Dog” or “Gizmo”, would be the one received by the second client.
另一个潜在问题是不一致性。当不同的服务在对同一块共享资源进行读、写时,可能是另一个服务或者数据,就会存在竞态条件的可能——当一些数据将被更新,但读操作先于更新发生——这类场景下数据就会发生不一致。例如,在图片托管这个场景下,竞争条件会发生在一个客户端发出将小狗图片标题由“Dog”更新为“Gizmo”的请求,但同时另一个客户端正在读取该图片这样的情况下。在这样的情况下,不清楚第二个客户端接收到的标题会是“Dog”还是“Gizmo”。
There are certainly some obstacles associated with partitioning data, but partitioning allows each problem to be split—by data, load, usage patterns, etc.—into manageable chunks. This can help with scalability and manageability, but is not without risk. There are lots of ways to mitigate risk and handle failures; however, in the interest of brevity they are not covered in this chapter. If you are interested in reading more, you can check out my blog post on fault tolerance and monitoring.
诚然,关于数据分区还存在很多阻碍,但分区通过数据、负载、用户使用模式等使得每个问题分解成易处理的部分。这样有助于可扩展性和可管理型,但也不是没有风险的。有很多方法能够用来降低风险和处理故障;但为了简化篇幅,本章就不深入(这些方法)了。如果你有兴趣想了解更多,可以查看我博客上发表的关于容错性和监控的博客文章。
1.3. The Building Blocks of Fast and Scalable Data Access 构建快速和可扩展的数据访问组件
Having covered some of the core considerations in designing distributed systems, let’s now talk about the hard part: scaling access to the data.
在讨论了设计分布式系统时的一些核心考虑因素之后,现在让我们来谈谈比较困难的部分:数据访问的可扩展性。
Most simple web applications, for example, LAMP stack applications, look something like Figure 1.5.
大多数简单的web应用程序,例如LAMP技术栈应用程序,看起来像图1.5。
 Figure 1.5: Simple web applications
Figure 1.5: Simple web applications
As they grow, there are two main challenges: scaling access to the app server and to the database. In a highly scalable application design, the app (or web) server is typically minimized and often embodies a shared-nothing architecture. This makes the app server layer of the system horizontally scalable. As a result of this design, the heavy lifting is pushed down the stack to the database server and supporting services; it’s at this layer where the real scaling and performance challenges come into play.
随着系统的成长,会有两个主要挑战:对应用服务器访问的可扩展性和对数据库访问的可扩展性。在一个高度可扩展的应用程序设计中,应用程序(或Web)服务器通常最小化,并且通常体现为非共享(无状态)架构。这使得系统的应用服务器层可以水平扩展。这种设计的结果是,压力被向下推到了数据库服务器和相关(底层)支持服务;真正的扩展和性能挑战就在这一层起到作用。
The rest of this chapter is devoted to some of the more common strategies and methods for making these types of services fast and scalable by providing fast access to data.
本章余下部分致力于介绍)一些更加通用的策略和方法,通过更快的数据访问使得这些类型的服务更加快速和可扩展。

Figure 1.6: Oversimplified web application
图1.6: 极简的web应用程序
Most systems can be oversimplified to Figure 1.6. This is a great place to start. If you have a lot of data, you want fast and easy access, like keeping a stash of candy in the top drawer of your desk. Though overly simplified, the previous statement hints at two hard problems: scalability of storage and fast access of data.
大多数系统可以极度简化为像图1.6这样的。这是一个很好的开始。如果你有大量的数据且希望快速、简单地访问,就像你把糖果藏在你桌子第一个抽屉里。虽然被极度简化,前面的观点仍暗示着两个难题:存储的可扩展性和数据的快速访问。
For the sake of this section, let’s assume you have many terabytes (TB) of data and you want to allow users to access small portions of that data at random. (See Figure 1.7.) This is similar to locating an image file somewhere on the file server in the image application example.
为了本节的目的,让我们假设你有数TB的数据,并希望用户能够随机访问该数据的一小部分。(请参见图1.7。)这就类似于在图片应用例子里定位文件服务器上一个图片文件的位置。。

Figure 1.7: Accessing specific data
图1.7:访问特定数据
This is particularly challenging because it can be very costly to load TBs of data into memory; this directly translates to disk IO. Reading from disk is many times slower than from memory—memory access is as fast as Chuck Norris, whereas disk access is slower than the line at the DMV. This speed difference really adds up for large data sets; in real numbers memory access is as little as 6 times faster for sequential reads, or 100,000 times faster for random reads, than reading from disk (see “The Pathologies of Big Data”, http://queue.acm.org/detail.cfm?id=1563874). Moreover, even with unique IDs, solving the problem of knowing where to find that little bit of data can be an arduous task. It’s like trying to get that last Jolly Rancher from your candy stash without looking.
由于很难将TB级的数据加载到内存,所以这会使事情变得非常有挑战性;这(种访问)将直接变为磁盘IO操作。从磁盘读取比从内存读取慢很多倍,访问速度和Chuck Norris(美国武术家,电影明星)一样快,而磁盘访问比DMV线还慢。这样的速度差异对于大数据来说比较客观(This speed difference really adds up for large data sets);顺序读方面访问内存的速度是访问磁盘的6倍,而在随机读方面,前者是后者的十万倍(参见”The Pathologies of Big Data”, http://queue.acm.org/detail.cfm?id=1563874)。而且,即使有唯一ID,从哪里能够找到这样一小块数据仍然是一项艰巨的任务。这就好比从你藏糖果的地方不看一眼地想拿到最后一块Jolly Rancher。
Thankfully there are many options that you can employ to make this easier; four of the more important ones are caches, proxies, indexes and load balancers. The rest of this section discusses how each of these concepts can be used to make data access a lot faster.
幸运的是,你有很多能把事情变得更加容易的选择;其中重要的有如下4个:缓存、代理、索引、负载均衡。本节的其余部分将讨论如何使用这些概念使数据访问更快。
Caches 缓存
Caches take advantage of the locality of reference principle: recently requested data is likely to be requested again. They are used in almost every layer of computing: hardware, operating systems, web browsers, web applications and more. A cache is like short-term memory: it has a limited amount of space, but is typically faster than the original data source and contains the most recently accessed items. Caches can exist at all levels in architecture, but are often found at the level nearest to the front end, where they are implemented to return data quickly without taxing downstream levels.
缓存利用了本地引用原则的好处:最近访问的数据可能被再次访问。缓存几乎被用在计算机运行的各层:硬件,操作系统,web浏览器,web应用等等。缓存就像短期的内存:有着限定大小的空间,但通常比访问原始数据源更快,并且包含有最近最多被访问过的(数据)项。缓存可以存在于架构的各个层次,但会发现到经常更靠近前端(非web前端界面,架构上层),这样就可尽快返回数据而不用经过繁重的下层(处理)了。
How can a cache be used to make your data access faster in our API example? In this case, there are a couple of places you can insert a cache. One option is to insert a cache on your request layer node, as in Figure 1.8.
在我们的API例子中,如何使用一个缓存来加速你的数据访问速度呢?在这个场景下,你可以在很多地方插入一个缓存。选择之一是在你的请求层节点中插入一个缓存,如图 1.8..
Figure 1.8: Inserting a cache on your request layer node
图1.8: 在请求层节点中插入缓存
Placing a cache directly on a request layer node enables the local storage of response data. Each time a request is made to the service, the node will quickly return local, cached data if it exists. If it is not in the cache, the request node will query the data from disk. The cache on one request layer node could also be located both in memory (which is very fast) and on the node’s local disk (faster than going to network storage).
将缓存直接放置在请求层节点中让本地存储响应数据变为可能。每次对于一个服务的请求,节点将立即返回存在的本地、缓存的数据。如果(对应的)缓存不存在,请求节点将会从磁盘中查询数据。请求层节点的缓存既可以放置在内存(更快)也可以在节点本地磁盘(比通过网络快)上。

Figure 1.9: Multiple caches
图1.9:多个缓存
What happens when you expand this to many nodes? As you can see in Figure 1.9, if the request layer is expanded to multiple nodes, it’s still quite possible to have each node host its own cache. However, if your load balancer randomly distributes requests across the nodes, the same request will go to different nodes, thus increasing cache misses. Two choices for overcoming this hurdle are global caches and distributed caches.
当你扩展到多个节点时,会发生什么呢?如图 1.9所示,如果请求层扩展到多个节点,那么每个节点都可以拥有它自身的缓存。但是,如果你的负载均衡器将请求随机分发到这些节点上,同样的请求会到达不同的节点,就会提高缓存miss率。两种克服这种困难的方法是:全局缓存和分布式缓存。
Global Cache 全局缓存
A global cache is just as it sounds: all the nodes use the same single cache space. This involves adding a server, or file store of some sort, faster than your original store and accessible by all the request layer nodes. Each of the request nodes queries the cache in the same way it would a local one. This kind of caching scheme can get a bit complicated because it is very easy to overwhelm a single cache as the number of clients and requests increase, but is very effective in some architectures (particularly ones with specialized hardware that make this global cache very fast, or that have a fixed dataset that needs to be cached).
正如听起来的一样,全局缓存是指:所有节点使用同一缓存空间。这包括增加一台服务器或是某种类型的文件存储,比从你原始存储地方(访问)更快,并且所有请求层的节点均可以访问(全局缓存)。所有请求节点统一像访问其本地缓存般访问(全局)缓存。这种类型的缓存机制可能会变得比较复杂,因为随着客户端和请求数量的增加,单个缓存(服务器)很容易被压垮,但是在一些架构中非常有效(特别是有专门定制的硬件使得访问全局缓存非常快速,或者需要缓存的数据集是固定的)。
There are two common forms of global caches depicted in the diagrams. In Figure 1.10, when a cached response is not found in the cache, the cache itself becomes responsible for retrieving the missing piece of data from the underlying store. In Figure 1.11 it is the responsibility of request nodes to retrieve any data that is not found in the cache.
通常有两种形式的全局缓存,如下图。图 1.10,中,如果缓存中找不到对应的响应,那缓存自身会去从下层存储中获取丢失的数据。在图1.11中,当缓存中找不到相应数据时,需要请求节点自己去获取数据。

Figure 1.10: Global cache where cache is responsible for retrieval
图1.10:全局缓存自身负责存取

Figure 1.11: Global cache where request nodes are responsible for retrieval
图1.11 全局缓存,请求节点负责存取
第一种方式相当于是全局缓存将查询缓存、底层获取数据、填充缓存这些操作一并做掉,理想情况下对于上层应用应该只需要提供一个获取数据的API,上层应用无需关心所请求的数据是已存在于缓存中的还是从底层存储中获取的,能够更专注于上层业务逻辑,但这就可能需要这种全局缓存设计成能够根据传入API接口的参数去获取底层存储的数据,译者认为接口签名可以简化为Object getData(String uniqueId, DataRetrieveCallback callback),第一个参数代表与缓存约定的唯一标示一个数据的ID,第二个是一个获取数据回调接口,具体实现由调用该接口的业务端来实现,即当全局缓存中未找到uniqueId对应的缓存数据时,那就会以该callback去获取数据,并以uniqueId为key、callback获取数据为value放入全局缓存中。第二种方式相对来说自由一些。请求节点自行根据业务场景需求来决定查询数据的方式,以及查数据后的处理(比如缓存回收策略),全局缓存只作为一个基础组件让请求节点能够在其中存取数据The majority of applications leveraging global caches tend to use the first type, where the cache itself manages eviction and fetching data to prevent a flood of requests for the same data from the clients. However, there are some cases where the second implementation makes more sense. For example, if the cache is being used for very large files, a low cache hit percentage would cause the cache buffer to become overwhelmed with cache misses; in this situation it helps to have a large percentage of the total data set (or hot data set) in the cache. Another example is an architecture where the files stored in the cache are static and shouldn’t be evicted. (This could be because of application requirements around that data latency—certain pieces of data might need to be very fast for large data sets—where the application logic understands the eviction strategy or hot spots better than the cache.)
大多数应用倾向于通过第一种方式使用全局缓存,由缓存自身来管理回收、获取数据,来应对从客户端发起的对同一数据的众多请求。但是,对于一些场景来说,第二种实现就比较有意义。比如,如果是用来缓存大型文件,那缓存低命中率将会导致缓存缓冲区被缓存miss给压垮;在这种情况下,缓存中缓存大部分数据集(或热门数据)将会有助解决这个问题。另一个例子是,一个架构中缓存的文件是静态、不应回收的。(这可能跟应用对于数据延迟的需求有关——对于大数据集来说,某些数据段需要被快速访问——这时应用的业务逻辑会比缓存更懂得回收策略或热点处理。)
Distributed Cache 分布式缓存
In a distributed cache (Figure 1.12), each of its nodes own part of the cached data, so if a refrigerator acts as a cache to the grocery store, a distributed cache is like putting your food in several locations—your fridge, cupboards, and lunch box—convenient locations for retrieving snacks from, without a trip to the store. Typically the cache is divided up using a consistent hashing function, such that if a request node is looking for a certain piece of data it can quickly know where to look within the distributed cache to determine if that data is available. In this case, each node has a small piece of the cache, and will then send a request to another node for the data before going to the origin. Therefore, one of the advantages of a distributed cache is the increased cache space that can be had just by adding nodes to the request pool.
在一个分布式缓存中(如图1.12),没个节点拥有部分缓存的数据,如果将杂货店里的冰箱比作一个缓存,那么一个分布式缓存好比是将你的食物放在几个不同的地方——你的冰箱、食物柜、午餐饭盒里——非常便于取到快餐的地方而无需跑一趟商店。通常这类缓存使用一致性Hash算法进行切分,这样一个请求节点在查询指定数据时,可以很快知道去哪里查询,并通过分布式缓存来判断数据可用性。这种场景下,每个节点都会拥有一部分缓存,并且会将请求传递到其他节点来获取数据,最后才到原始地方查询数据。因此,分布式缓存的一个优势就是通过往请求池里增加节点来扩大缓存空间。
A disadvantage of distributed caching is remedying a missing node. Some distributed caches get around this by storing multiple copies of the data on different nodes; however, you can imagine how this logic can get complicated quickly, especially when you add or remove nodes from the request layer. Although even if a node disappears and part of the cache is lost, the requests will just pull from the origin—so it isn’t necessarily catastrophic!
分布式缓存的一个缺点在于节点丢失纠正问题。一些分布式缓存通过将复制数据多份存放在不同的节点来解决这个问题;但是,你可以想象到这样做会让逻辑迅速变得复杂,特别是当你向请求层增加或减少节点的时候。虽然一个节点丢失并且缓存失效,但请求仍然可以从源头来获取(数据)——所以这不一定是最悲剧的。
 Figure 1.12: Distributed cache
Figure 1.12: Distributed cache
The great thing about caches is that they usually make things much faster (implemented correctly, of course!) The methodology you choose just allows you to make it faster for even more requests. However, all this caching comes at the cost of having to maintain additional storage space, typically in the form of expensive memory; nothing is free. Caches are wonderful for making things generally faster, and moreover provide system functionality under high load conditions when otherwise there would be complete service degradation.
缓存的伟大之处在于它们让事情进行的更快(当然需要执行正确)。你所选择的方法只是让你能够更快处理更多的请求。但是,这些缓存是以需要维护更多存储空间为代价的,特别是昂贵的内存方式;天下没有免费的午餐。缓存让事情变得更快,同时还保证了高负载条件下系统的功能,否则(系统)服务可能早已降级。
One example of a popular open source cache is Memcached (http://memcached.org/) (which can work both as a local cache and distributed cache); however, there are many other options (including many language- or framework-specific options).
一个非常受欢迎的开源缓存叫做Memcached(http://memcached.org/)(既可以是本地又可以是分布式缓存);但是,还有很多其他选择(包括许多语言/框架特定选择)。
Memcached is used in many large web sites, and even though it can be very powerful, it is simply an in-memory key value store, optimized for arbitrary data storage and fast lookups (O(1)).
Memcached被应用于许多大型web网站,纵然它功能强大,但它简单来说就是一个内存key-value存储,对任意数据存储和快速查找做了优化(时间复杂度O(1))。
Facebook uses several different types of caching to obtain their site performance (see “Facebook caching and performance”). They use $GLOBALS and APC caching at the language level (provided in PHP at the cost of a function call) which helps make intermediate function calls and results much faster. (Most languages have these types of libraries to improve web page performance and they should almost always be used.) Facebook then use a global cache that is distributed across many servers (see “Scaling memcached at Facebook”), such that one function call accessing the cache could make many requests in parallel for data stored on different Memcached servers. This allows them to get much higher performance and throughput for their user profile data, and have one central place to update data (which is important, since cache invalidation and maintaining consistency can be challenging when you are running thousands of servers).
Facebook使用了若干种不同类型的缓存以达到他们网站的性能(参见“Facebook caching and performance“)。他们在语言层面使用$GLOBALS和APC缓存(在PHP中提供的函数调用)使得中间功能调用和(得到)结果更加快速。(大多数语言都有这种类型的类库来提高web性能,应该经常去使用。)Facebook使用一种全局缓存,分布在多台服务器上(参见”Scaling memcached at Facebook“),这样一个访问缓存的函数调用就会产生很多并行请求来从Memcached服务器(集群)获取数据。这使得他们能够在用户概况数据上获得更高的性能和吞吐量,并且有一个集中的地方去更新数据(当你运行着数以千计的服务器时,缓存失效、管理一致性都将变得很有挑战,所以这是很重要的)。
Now let’s talk about what to do when the data isn’t in the cache…
现在让我们来聊聊缓存失效的时候应该做什么。
Proxies 代理
At a basic level, a proxy server is an intermediate piece of hardware/software that receives requests from clients and relays them to the backend origin servers. Typically, proxies are used to filter requests, log requests, or sometimes transform requests (by adding/removing headers, encrypting/decrypting, or compression).
从基本层面来看,代理服务器是硬件/软件的一个中间层,用于接收从客户端发起的请求并传递到后端服务器。通常来说,代理是用来过滤请求、记录请求日志或者有时对请求进行转换(增加/去除头文件,加密/解密或者进行压缩)。

Figure 1.13: Proxy server
图1.13:代理服务器
Proxies are also immensely helpful when coordinating requests from multiple servers, providing opportunities to optimize request traffic from a system-wide perspective. One way to use a proxy to speed up data access is to collapse the same (or similar) requests together into one request, and then return the single result to the requesting clients. This is known as collapsed forwarding.
代理同样能够极大帮助协调多个服务器的请求,有机会从系统的角度来优化请求流量。使用代理来加快数据访问速度的方式之一是将多个同种请求集中放到一个请求中,然后将单个结果返回到请求客户端。这就叫做压缩转发。
Imagine there is a request for the same data (let’s call it littleB) across several nodes, and that piece of data is not in the cache. If that request is routed thought the proxy, then all of those requests can be collapsed into one, which means we only have to read littleB off disk once. (See Figure 1.14.) There is some cost associated with this design, since each request can have slightly higher latency, and some requests may be slightly delayed to be grouped with similar ones. But it will improve performance in high load situations, particularly when that same data is requested over and over. This is similar to a cache, but instead of storing the data/document like a cache, it is optimizing the requests or calls for those documents and acting as a proxy for those clients.
假设在几个节点上存在对同样数据的请求(我们叫它littleB),并且这份数据不在缓存里。如果请求通过代理路由,那么这些请求可以被压缩为一个,就意味着我们只需要从磁盘读取一次littleB即可。(见图1.14)这种设计是会带来一定的开销,因为每个请求都会产生更高的延迟(跟不用代理相比),并且一些请求会因为要与相同请求合并而产生一些延迟。但这种做法在高负载的情况下提高系统性能,特别是当相同的数据重复被请求。这很像缓存,但不用像缓存那样存储数据/文件,而是优化了对那些文件的请求或调用,并且充当那些客户端的代理。
In a LAN proxy, for example, the clients do not need their own IPs to connect to the Internet, and the LAN will collapse calls from the clients for the same content. It is easy to get confused here though, since many proxies are also caches (as it is a very logical place to put a cache), but not all caches act as proxies.
例如,在局域网(LAN)代理中,客户端不需有自己的IP来连接互联网,而局域网会将对同样内容的客户端请求进行压缩。这里可能很容易产生困惑,因为许多代理同样也是缓存(因为在这里放一个缓存很合理),但不是所有缓存都能充当代理。

Figure 1.14: Using a proxy server to collapse requests
图1.14:使用一个代理服务器来压缩请求
Another great way to use the proxy is to not just collapse requests for the same data, but also to collapse requests for data that is spatially close together in the origin store (consecutively on disk). Employing such a strategy maximizes data locality for the requests, which can result in decreased request latency. For example, let’s say a bunch of nodes request parts of B: partB1, partB2, etc. We can set up our proxy to recognize the spatial locality of the individual requests, collapsing them into a single request and returning only bigB, greatly minimizing the reads from the data origin. (See Figure 1.15.) This can make a really big difference in request time when you are randomly accessing across TBs of data! Proxies are especially helpful under high load situations, or when you have limited caching, since they can essentially batch several requests into one.
另一个使用代理的好方法是,不单把代理用来压缩对同样数据的请求,还可以用来压缩对那些在原始存储中空间上紧密联系的数据(磁盘连续块)的请求。使用这一策略最大化(利用)所请求数据的本地性,可以减少请求延迟。例如,我们假设一群节点请求B的部分(数据):B1, B2,等。我们可以对代理进行设置使其能够识别出不同请求的空间局部性,将它们压缩为单个请求并且只返回bigB,最小化对原始数据的读取操作。(见图1.15)当你随机访问TB级的数据时,这样会大幅改变(降低)请求时间。在高负载情况下或者当你只有有限的缓存,代理是非常有帮助的,因为代理可以从根本上将若干个请求合并为一个。

Figure 1.15: Using a proxy to collapse requests for data that is spatially close together
图1.15:使用代理压缩空间上邻近的数据请求
It is worth noting that you can use proxies and caches together, but generally it is best to put the cache in front of the proxy, for the same reason that it is best to let the faster runners start first in a crowded marathon race. This is because the cache is serving data from memory, it is very fast, and it doesn’t mind multiple requests for the same result. But if the cache was located on the other side of the proxy server, then there would be additional latency with every request before the cache, and this could hinder performance.
你完全可以将代理和缓存一起使用,但通常最好将缓存放在代理之前使用,正如在马拉松赛跑中最好让跑得快的选手跑在前面。这是因为缓存通过内存来提供数据非常快速,并且它也不关心多个对同样结果的请求。但如果缓存被放在代理服务器的另一边(后面),那在每个请求访问缓存前就会有额外的延迟,这会阻碍系统性能。
If you are looking at adding a proxy to your systems, there are many options to consider; Squid and Varnish have both been road tested and are widely used in many production web sites. These proxy solutions offer many optimizations to make the most of client-server communication. Installing one of these as a reverse proxy (explained in the load balancer section below) at the web server layer can improve web server performance considerably, reducing the amount of work required to handle incoming client requests.
如果你在寻找一款代理想要加入到你的系统中,那有很多选择可供考虑;Squid和Varnish都是经过路演并广泛应用于很多网站的生产环境中。这些代理方案做了很多优化来充分使用客户端与服务端的通信。安装其中之一并在web服务器层将其作为一个反向代理(将在下面的负载均衡小节解释)可以提高web服务器相当大的性能,降低处理来自客户端的请求所消耗的工作量。
Indexes 索引
Using an index to access your data quickly is a well-known strategy for optimizing data access performance; probably the most well known when it comes to databases. An index makes the trade-offs of increased storage overhead and slower writes (since you must both write the data and update the index) for the benefit of faster reads.
使用索引来加快访问数据已经是优化数据访问性能众所周知的策略;可能更多来自数据库。索引是以增加存储开销和减慢写入速度(因为你必须同时写入数据并更新索引)的代价来得到更快读取的好处。
Just as to a traditional relational data store, you can also apply this concept to larger data sets. The trick with indexes is you must carefully consider how users will access your data. In the case of data sets that are many TBs in size, but with very small payloads (e.g., 1 KB), indexes are a necessity for optimizing data access. Finding a small payload in such a large data set can be a real challenge since you can’t possibly iterate over that much data in any reasonable time. Furthermore, it is very likely that such a large data set is spread over several (or many!) physical devices—this means you need some way to find the correct physical location of the desired data. Indexes are the best way to do this.
就像对于传统的关系数据库,你同样可以将这种概念应用到大数据集上。索引的诀窍在于你必须仔细考虑你的用户会如何使用你的数据。对于TB级但单项数据比较小(比如1KB)的数据集,索引是优化数据访问非常必要的方式。在一个大数据集中寻找一个小单元是非常困难的,因为你不可能在一个可接受的时间里遍历这么大的数据。并且,像这么一个大数据集很有可能是分布在几个(或更多)物理设备上——这就意味着你需要有方法能够找到所要数据正确的物理位置。索引是达到这个的最好方法。

Figure 1.16: Indexes
图1.16:索引
An index can be used like a table of contents that directs you to the location where your data lives. For example, let’s say you are looking for a piece of data, part 2 of B—how will you know where to find it? If you have an index that is sorted by data type—say data A, B, C—it would tell you the location of data B at the origin. Then you just have to seek to that location and read the part of B you want. (See Figure 1.16.)
索引可以像一张可以引导你至所要数据位置的表格来使用。例如,我们假设你在寻找B的part2数据——你将如何知道到哪去找到它?如果你有一个按照数据类型(如A,B,C)排序好的索引,它会告诉你数据B在哪里。然后你查找到位置,然后读取你所要的部分。(见图1.16)
These indexes are often stored in memory, or somewhere very local to the incoming client request. Berkeley DBs (BDBs) and tree-like data structures are commonly used to store data in ordered lists, ideal for access with an index.
这些索引通常存放在内存中,或者在更靠近客户端请求的地方。伯克利数据库(BDBs)和树形数据结构经常用来有序地存储数据,非常适合通过索引来访问。
Often there are many layers of indexes that serve as a map, moving you from one location to the next, and so forth, until you get the specific piece of data you want. (See Figure 1.17.)
索引经常会有很多层,类似一个map,将你从一个地方引导至另一个,以此类推,直到你获取到你所要的那份数据。(见图1.17)
 Figure 1.17: Many layers of indexes
Figure 1.17: Many layers of indexes
图1.17:多层索引
Indexes can also be used to create several different views of the same data. For large data sets, this is a great way to define different filters and sorts without resorting to creating many additional copies of the data.
索引也可以用来对同样的数据创建出一些不同的视图。对于大数据集来说,通过定义不同的过滤器和排序是一个很好的方式,而不需要创建很多额外数据拷贝。
For example, imagine that the image hosting system from earlier is actually hosting images of book pages, and the service allows client queries across the text in those images, searching all the book content about a topic, in the same way search engines allow you to search HTML content. In this case, all those book images take many, many servers to store the files, and finding one page to render to the user can be a bit involved. First, inverse indexes to query for arbitrary words and word tuples need to be easily accessible; then there is the challenge of navigating to the exact page and location within that book, and retrieving the right image for the results. So in this case the inverted index would map to a location (such as book B), and then B may contain an index with all the words, locations and number of occurrences in each part.
例如,假设之前的图片托管系统就是在管理书页上的图片,并且服务能够允许客户端查询图片中的文字,按照标题搜索整本书的内容,就像搜索引擎允许你搜索HTML内容一样。这种场景下,所有书中的图片需要很多很多的服务器去存储文件,查找到其中一页渲染给用户将会是比较复杂的。首先,对需要易于查询的任意单词、词组进行倒排索引;然后挑战在于导航至那本书具体的页面、位置并获取到正确的图片。所以,在这一场景,倒排索引将会映射到一个位置(比如B书),然后B可能会包含每个部分的所有单词、位置、出现次数的索引。
An inverted index, which could represent Index1 in the diagram above, might look something like the following—each word or tuple of words provide an index of what books contain them.
倒排索引可能如同下图——每个单词或词组会提供一个哪些书包含它的索引。
| Word(s) | Book(s) |
|---|---|
| being awesome | Book B, Book C, Book D |
| always | Book C, Book F |
| believe | Book B |
The intermediate index would look similar but would contain just the words, location, and information for book B. This nested index architecture allows each of these indexes to take up less space than if all of that info had to be stored into one big inverted index.
这种中间索引看上去都类似,仅会包含单词、位置和B的一些信息。这种嵌套索引的架构允许每个索引占用更少的空间而非将所有的信息存放在一个巨大的倒排索引中。
And this is key in large-scale systems because even compressed, these indexes can get quite big and expensive to store. In this system if we assume we have a lot of the books in the world—100,000,000 (see Inside Google Books blog post)—and that each book is only 10 pages long (to make the math easier), with 250 words per page, that means there are 250 billion words. If we assume an average of 5 characters per word, and each character takes 8 bits (or 1 byte, even though some characters are 2 bytes), so 5 bytes per word, then an index containing only each word once is over a terabyte of storage. So you can see creating indexes that have a lot of other information like tuples of words, locations for the data, and counts of occurrences, can add up very quickly.
在大型可伸缩的系统中,即使索引已被压缩但仍会变得很大,不易存储。在这个系统里,我们假设世界上有很多书——100,000,000本——并且每本书仅有10页(为了便于计算),每页有250个单词,这就意味着一共有2500亿个单词。如果我们假设平均每个单词有5个字符,每个字符占用8个比特,每个单词5个字节,那么对于仅包含每个单词的索引的大小就达到TB级。所以你会发现创建像一些如词组、数据位置、出现次数之类的其他信息的索引将会增长得更快。
Creating these intermediate indexes and representing the data in smaller sections makes big data problems tractable. Data can be spread across many servers and still accessed quickly. Indexes are a cornerstone of information retrieval, and the basis for today’s modern search engines. Of course, this section only scratched the surface, and there is a lot of research being done on how to make indexes smaller, faster, contain more information (like relevancy), and update seamlessly. (There are some manageability challenges with race conditions, and with the sheer number of updates required to add new data or change existing data, particularly in the event where relevancy or scoring is involved).
创建这些中间索引并且以更小的方式表达数据,将大数据的问题变得易于处理。数据可以分布在多台服务器但仍可以快速访问。索引是信息获取的基石,也是当今现代搜索引擎的基础。当然,这一小节仅仅是揭开表面,为了把索引变得更小、更快、包含更多信息(比如关联)、无缝更新,还有大量的研究工作要做。(还有一些可管理性方面的挑战,比如竞争条件、增加或修改数据所带来的更新操作,特别是再加上关联、scoring)
Being able to find your data quickly and easily is important; indexes are an effective and simple tool to achieve this.
能够快速、简单地找到你的数据非常重要;索引是达到这一目标非常有效、简单的工具。
Load Balancers 负载均衡器
Finally, another critical piece of any distributed system is a load balancer. Load balancers are a principal part of any architecture, as their role is to distribute load across a set of nodes responsible for servicing requests. This allows multiple nodes to transparently service the same function in a system. (See Figure 1.18.) Their main purpose is to handle a lot of simultaneous connections and route those connections to one of the request nodes, allowing the system to scale to service more requests by just adding nodes.
另一个任何分布式系统的关键组件是负载均衡器。负载均衡器是任何架构的关键部分,用于将负载分摊在一些列负责服务请求的节点上。这使得一个系统的多个节点能够为相同功能提供服务。(见图1.18)它们主要目的是处理许多同时进行的连接并将这些连接路由到其中的一个请求节点上,使得系统能够可伸缩地通过增加节点来服务更多请求。

Figure 1.18: Load balancer
图1.18 负载均衡器
There are many different algorithms that can be used to service requests, including picking a random node, round robin, or even selecting the node based on certain criteria, such as memory or CPU utilization. Load balancers can be implemented as software or hardware appliances. One open source software load balancer that has received wide adoption is HAProxy).
有很多不同的用于服务请求的算法,包括随机挑选一个节点、循环(round robin)或给予某些标准如内存/CPU使用率选取节点。一个广泛使用的开源软件级负载均衡器是HAProxy。
In a distributed system, load balancers are often found at the very front of the system, such that all incoming requests are routed accordingly. In a complex distributed system, it is not uncommon for a request to be routed to multiple load balancers as shown inFigure 1.19.
在一个分布式系统中,负责均衡器通常是放置在系统很前端的地方,这样就能路由所有进入(系统)的请求。在一个复杂的分布式系统中,一个请求被多个负载均衡器路由也不是不可能。(见图1.19)

Figure 1.19: Multiple load balancers
图1.19:多重负责均衡器
Like proxies, some load balancers can also route a request differently depending on the type of request it is. (Technically these are also known as reverse proxies.)
如同代理一般,一些负载均衡器也能根据不同类型的请求进行路由。(从技术上来说,就是所谓的反向代理。)
One of the challenges with load balancers is managing user-session-specific data. In an e-commerce site, when you only have one client it is very easy to allow users to put things in their shopping cart and persist those contents between visits (which is important, because it is much more likely you will sell the product if it is still in the user’s cart when they return). However, if a user is routed to one node for a session, and then a different node on their next visit, there can be inconsistencies since the new node may be missing that user’s cart contents. (Wouldn’t you be upset if you put a 6 pack of Mountain Dew in your cart and then came back and it was empty?) One way around this can be to make sessions sticky so that the user is always routed to the same node, but then it is very hard to take advantage of some reliability features like automatic failover. In this case, the user’s shopping cart would always have the contents, but if their sticky node became unavailable there would need to be a special case and the assumption of the contents being there would no longer be valid (although hopefully this assumption wouldn’t be built into the application). Of course, this problem can be solved using other strategies and tools in this chapter, like services, and many not covered (like browser caches, cookies, and URL rewriting).
负载均衡器的挑战之一在于(如何)管理用户session数据。在一个电子商务网站,当你只有一个客户端时很容易让用户把东西放到他们的购物车并且在不同的访问间保存(这是很重要的,因为当用户回来时很有可能买放在购物车里的产品)。但是,如果一个用户先被路由到一个session节点,然后在他们下次访问时路由到另一个不同的节点,那将会因为新节点可能丢失用户购物车里的东西而产生不一致。(如果你精心挑选了6包Mountain Dew放到购物车,但当你回来的时候发现购物车清空了,你会不会很沮丧?)解决办法之一通过粘性session机制总是将用户路由到同一节点,但这样既很难享受到一些像自动failover的可靠机制了。在这一场景下,用户的购物车总是会有东西的,如果他们所对应的粘性节点不可用了,那么就会是一个特殊情况对于(保存)在那里的东西的假设就无效了(当然我们希望这种假设不会出现在应用里)。当然,这个问题可以通过本章中的一些其他策略或者工具来解决,比如服务,还有一些没有提到的(如浏览器缓存、cookie、URL地址重写)。
If a system only has a couple of a nodes, systems like round robin DNS may make more sense since load balancers can be expensive and add an unneeded layer of complexity. Of course in larger systems there are all sorts of different scheduling and load-balancing algorithms, including simple ones like random choice or round robin, and more sophisticated mechanisms that take things like utilization and capacity into consideration. All of these algorithms allow traffic and requests to be distributed, and can provide helpful reliability tools like automatic failover, or automatic removal of a bad node (such as when it becomes unresponsive). However, these advanced features can make problem diagnosis cumbersome. For example, when it comes to high load situations, load balancers will remove nodes that may be slow or timing out (because of too many requests), but that only exacerbates the situation for the other nodes. In these cases extensive monitoring is important, because overall system traffic and throughput may look like it is decreasing (since the nodes are serving less requests) but the individual nodes are becoming maxed out.
如果系统只是由少数节点构成的,那么像Round Robin DNS那样的系统就更加明智,因为负责均衡器很贵而且增加了一层不必要的复杂度。当然在大型系统里有各种各样的调度和负载均衡算法,包括简单的像随机选择或循环方式,还有更加复杂的机制如考虑(系统)使用率和容量的。所有这些算法都分布化了流量和请求,并且提供像自动failover或者自动去除坏节点(当该节点失去响应后)这类对可靠性非常有帮助的工具。但是,这些先进特性也会使得问题诊断变得复杂化。比如,在一个高负载情况下,负载均衡器会去除掉那些变慢或者超时(由于请求过多)的节点,但这样反而加重了其他节点的(恶劣)处境。在这些情况下,全面监控变得很重要,因为从全局来看系统的流量和吞吐量正在下降(由于各节点服务请求越来越少),但从节点个体来看正在达到极限。
Load balancers are an easy way to allow you to expand system capacity, and like the other techniques in this article, play an essential role in distributed system architecture. Load balancers also provide the critical function of being able to test the health of a node, such that if a node is unresponsive or over-loaded, it can be removed from the pool handling requests, taking advantage of the redundancy of different nodes in your system.
负载均衡器是一个非常简单能让你提高系统容量的方法,并且像本文其他的技术一样,在分布式系统架构中扮演者重要角色。负载均衡器还能用来判断一个节点的健康度,这样当一个节点失去响应或者过载时,得益于系统不同节点的冗余性,可以将其从请求处理池中去除。
Queues 队列
So far we have covered a lot of ways to read data quickly, but another important part of scaling the data layer is effective management of writes. When systems are simple, with minimal processing loads and small databases, writes can be predictably fast; however, in more complex systems writes can take an almost non-deterministically long time. For example, data may have to be written several places on different servers or indexes, or the system could just be under high load. In the cases where writes, or any task for that matter, may take a long time, achieving performance and availability requires building asynchrony into the system; a common way to do that is with queues.
至此,我们已经覆盖了很多用于加快数据读取的方法,另一个扩展数据层的重要部分是有效管理写入操作。当系统比较简单,系统处理负载很低,数据库也很小,可以预见写入操作是很快的;但是,在更加复杂的系统中,写入操作的时间可能无法确定。例如,数据需要被写入到不同服务器或索引的多个地方,或者系统负载很高。这些情况下,由于上面的原因,写操作或者任何任务都会花费很长的时间,这时需要异步化系统才能提高系统的性能和可靠性;通常的方法之一是使用队列。

Figure 1.20: Synchronous request
图1.20:同步化请求
Imagine a system where each client is requesting a task to be remotely serviced. Each of these clients sends their request to the server, where the server completes the tasks as quickly as possible and returns the results to their respective clients. In small systems where one server (or logical service) can service incoming clients just as fast as they come, this sort of situation should work just fine. However, when the server receives more requests than it can handle, then each client is forced to wait for the other clients’ requests to complete before a response can be generated. This is an example of a synchronous request, depicted in Figure 1.20.
假设在一个系统中,每个客户端在请求远程服务来处理任务。每个客户端将其请求送至服务器,服务器尽可能快地完成这些任务并返回结果给相应的客户端。在小型系统中,当一台服务器(或者逻辑上的一个服务)可以尽快地服务到来的客户端(请求),这种情况下(系统)工作会比较好。但是,当服务器接收到超过其处理能力的请求时,那每个客户端都只能被迫等待其他客户端请求完成才能得到响应。图1.20描绘的就是一个同步请求的例子。
This kind of synchronous behavior can severely degrade client performance; the client is forced to wait, effectively performing zero work, until its request can be answered. Adding additional servers to address system load does not solve the problem either; even with effective load balancing in place it is extremely difficult to ensure the even and fair distribution of work required to maximize client performance. Further, if the server handling requests is unavailable, or fails, then the clients upstream will also fail. Solving this problem effectively requires abstraction between the client’s request and the actual work performed to service it.
这种同步的方式将会严重降低客户端性能;客户端被强制等待,在请求被响应前什么都做不了。增加额外的服务器并不能解决这个问题;即使通过有效的负载均衡,依然难以保证最大化客户端性能所需做的公平分配的工作。更进一步来说,当处理请求的服务器不可用或挂掉了,那么上游的客户端同样也会失败。有效解决这个问题需要抽象化客户端的请求和真正服务它所做的工作。

Figure 1.21: Using queues to manage requests
图1.21:使用队列来管理请求
When designing any sort of web application it is important to consider these key principles, even if it is to acknowledge that a design may sacrifice one or more of them.
在设计任何类型的Web应用程序时,考虑这些关键原则很重要,即使承认设计可能会牺牲其中的一个或多个原则。
Enter queues. A queue is as simple as it sounds: a task comes in, is added to the queue and then workers pick up the next task as they have the capacity to process it. (See Figure 1.21.) These tasks could represent simple writes to a database, or something as complex as generating a thumbnail preview image for a document. When a client submits task requests to a queue they are no longer forced to wait for the results; instead they need only acknowledgement that the request was properly received. This acknowledgement can later serve as a reference for the results of the work when the client requires it.
现在进入队列环节。一个队列,正如听上去的,简单来说就是当一个任务过来时,会被加入到队列中,然后会有当前有能力处理(任务)的worker去取下一个任务来做。(见图1.21。)这些任务可以是对数据库的写入操作,或是复杂一些的如生成文件的小型预览图。当一个客户端将任务的请求提交到队列后,它们不再需要被迫等待结果;取而代之的是,它们只需要确认请求被得到正确接收。当客户端需要的时候,这个确认此后可以当做是任务结果的引用。
Queues enable clients to work in an asynchronous manner, providing a strategic abstraction of a client’s request and its response. On the other hand, in a synchronous system, there is no differentiation between request and reply, and they therefore cannot be managed separately. In an asynchronous system the client requests a task, the service responds with a message lacknowledging the task was received, and then the client can periodically check the status of the task, only requesting the result once it has completed. While the client is waiting for an asynchronous request to be completed it is free to perform other work, even making asynchronous requests of other services. The latter is an example of how queues and messages are leveraged in distributed systems.
队列使得客户端能够以异步的方式进行工作,至关重要地抽象了一个客户端请求及其响应。另一方面,一个同步化系统不会区分请求和响应,因此就无法分开管理。在一个异步化系统里,客户端提交任务请求,后端服务反馈一个收到任务的确认信息,并且客户端可以定期地查看任务的状态,一旦完成即可取得任务结果。在客户端等待一个异步请求完成时,它可以自由地处理其他的工作,即使是发起对其他服务的异步请求。上面第二个就是分布式系统中采用队列和消息的例子。
Queues also provide some protection from service outages and failures. For instance, it is quite easy to create a highly robust queue that can retry service requests that have failed due to transient server failures. It is more preferable to use a queue to enforce quality-of-service guarantees than to expose clients directly to intermittent service outages, requiring complicated and often-inconsistent client-side error handling.
队列还能提供对服务断供/失败的保护措施。比如,很容易创建一个健壮的队列来重试那些由于服务器短暂失败的服务请求。更好的是通过使用队列来确保服务品质,而非将客户端直接面对断断续续的服务,因为那样会需要客户端复杂且经常不一致的错误处理。
Queues are fundamental in managing distributed communication between different parts of any large-scale distributed system, and there are lots of ways to implement them. There are quite a few open source queues like RabbitMQ, ActiveMQ, BeanstalkD, but some also use services like Zookeeper, or even data stores like Redis.
队列是管理大型可伸缩分布式应用不同部分间通信的基础,可以通过很多方式来实现。有一些开源的队列如RabbitMQ, ActiveMQ, BeanstalkD,也有一些使用像Zookeeper的服务,还有像Redis那样的数据存储。
1.4. Conclusion 总结
Designing efficient systems with fast access to lots of data is exciting, and there are lots of great tools that enable all kinds of new applications. This chapter covered just a few examples, barely scratching the surface, but there are many more—and there will only continue to be more innovation in the space.
设计出能够快速访问大量数据的高效系统(的方法)是一件激动人心的事情,并且又很多非常棒的工具来帮助各种各样的新应用来达到这一点。本章只覆盖了少量例子,仅仅是掀开了面纱,但其实还有更多,并将继续保持创新。